从计算机架构说起
一个定律的黄昏 一个时代的开启
摩尔定律是由英特尔(Intel)创始人之一戈登·摩尔(Gordon Moore)提出来的。其内容为:当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将提升一倍。
可以看出,指数增长的集成电路晶体管密度是驱动人类社会飞速发展的稳定动力。比如,互联网和计算科学的发展,以及相比从前便宜太多的基因测序等等。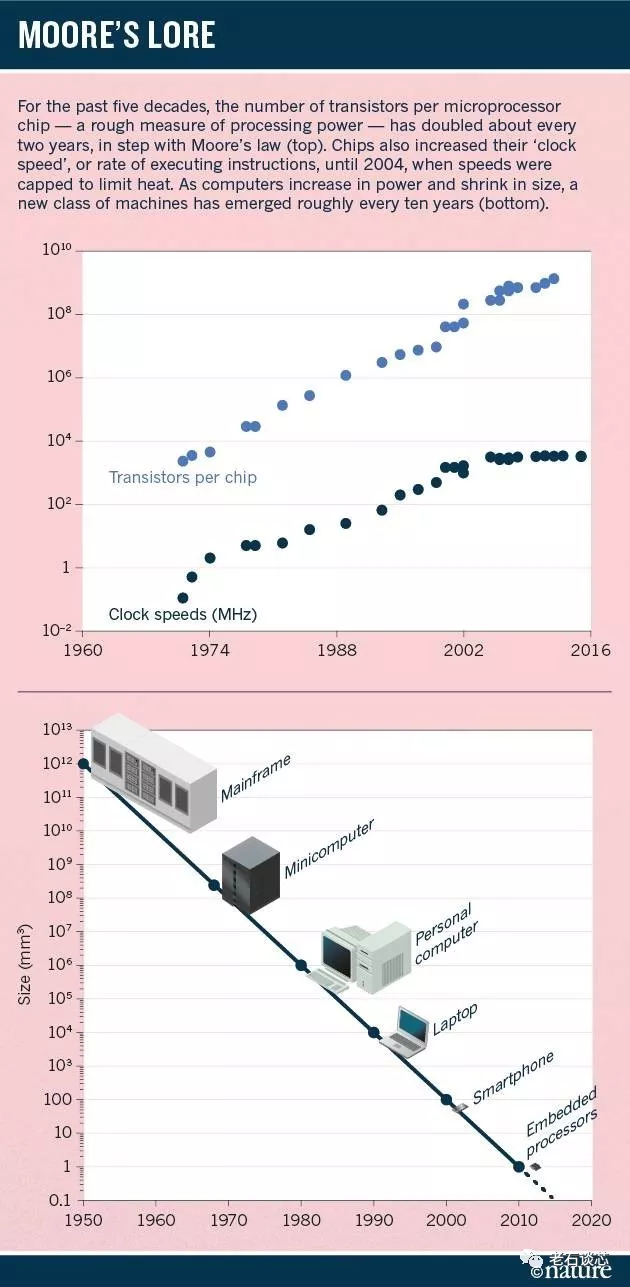
然而,近些年来,摩尔定律正在逐渐放缓。从技术上讲,随着晶体管尺度小得不可思议的情况下,其复杂性和差错率也将呈指数增长,同时也使全面而彻底的芯片测试几乎成为不可能。一旦芯片上线条的宽度达到纳米(10^-9米)数量级时,相当于只有几个分子的大小,这种情况下材料的物理、化学性能将发生质的变化,致使采用现行工艺的半导体器件不能正常工作。从经济上讲,随着尺度越来越小,集成度越来越高,成本增长得更加块。
传统的晶体管是个非常简单的结构,而现在已经演变成了非常复杂的3D结构。所以,如果我们尝试继续缩小晶体管的尺寸,就会更加复杂。例如,需要控制量子隧穿效应,以减少漏电流的产生,这就像当我们关闭开关时,它就应该完全关闭。对于这些问题,人们总是能够找到很多极具创意的解决方法,如台积电的FinFET技术,只不过越来越难了。
在传统的计算机体系架构的基础上,摩尔定律带来的收益正在递减。因此出现了很多诸如神经计算的新计算范式。但是对于硬件来说,维持摩尔定律还是需要依靠架构的创新。
2019年,两位图灵奖得主John Hennessy 和David Patterson 发表论文《A New Golden Age for Computer Architecture
》,计算机体系架构已经进入新的黄金时代。传统架构显然已经无法满足现有的数据处理任务,更不用说应对未来的需求,行业亟需架构的创新。
计算机架构的发展
软件与硬件的通信是通过指令集架构(ISA,Instruction Set Architecture)进行的,过去的几十年里它也一直在发展。
在微编程的驱动下,IBM在1964年宣布了他们新 System/360 ISA 的 4 种型号,革新了计算机的行业。
当计算机开始使用集成电路时,摩尔定律意味着控制存储器可以变大很多。更大的内存反过来又意味着允许使用更复杂的 ISA。英特尔在1986年发布了8086微处理器,成为了市场的选择。
80年代,硬件/软件接口的显著改进为架构创新带来了机会,计算机也逐渐从选择复杂指令集(Complex Instruction Set Computing,CISC)到精简指令集(Reduced Instruction Set Computing,RISC)。同时,业界也推出了一些量化架构的测量方法和基准。
下一个 ISA 创新应该是对 RISC 和 CISC 的继承。超长指令字(VLIW)及其表亲显式并行指令计算机(Explicitly Parallel Instruction Computing,EPIC)使用了宽指令,其中在每条指令中捆绑了多个独立操作。与 RISC 方法一样,VLIW 和 EPIC 将工作从硬件转移到编译器。同时市场选择 64 位版本的 x86 成为 32 位 x86 的继承者。
如今, RISC 正在后 PC 时代占据主导几十年来,都没有出现新的 CISC ISA。令我们惊讶的是,在推出 35 年后,今天对于通用处理器来说,最佳的 ISA 仍然是 RISC。
计算机架构未来机遇:DSA
尽管摩尔定律已经持续了几十年,但在 2000 年左右开始放缓。到了 2018 年,根据摩尔定律得出的预测与当下实际能力差了 15 倍。根据当前预测,这一差距将持续拉大,因为 CMOS 技术方法已经接近极限。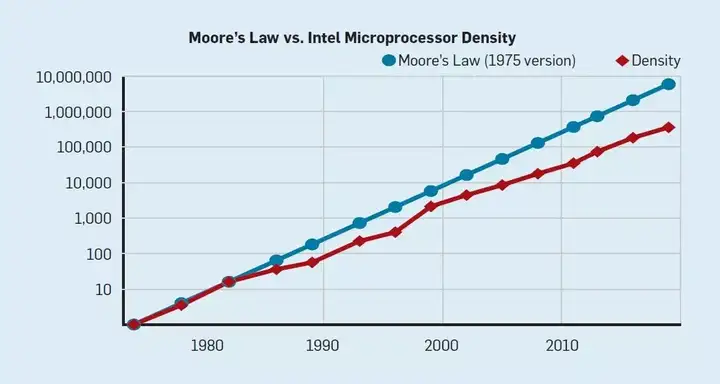
伴随摩尔定律是由罗伯特·登纳德(Robert Dennard)预测的登纳德缩放定律(Dennard scaling)。他指出,随着晶体管密度的增加,每个晶体管的能耗将降低,因此硅芯片上每平方毫米上的能耗几乎保持恒定。由于每平方毫米硅芯片的计算能力随着技术的迭代而不断增强,计算机将变得更加节能。登纳德缩放定律从 2007 年开始大幅放缓,2012 年左右接近失效。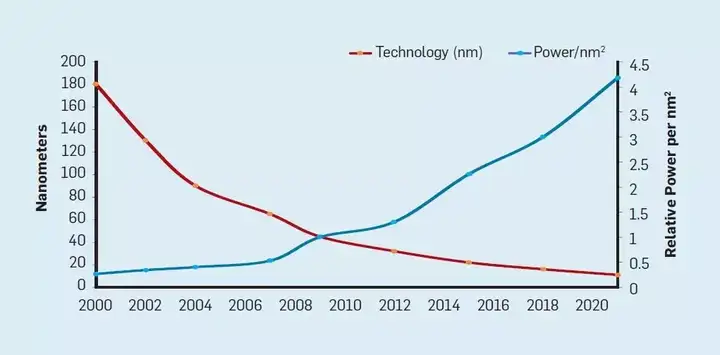
1986 年至 2002 年间,指令级并行(ILP)是提高性能的主要架构方法。而且随着晶体管速度的提高,其性能每年能提高 50% 左右。登纳德缩放定律的终结意味着工程师必须找到更加高效的并行化利用方法。于是在架构师的推动下,多核时代来临了。
多核将识别并行性和决定如何利用并行性的责任转移给程序员和语言系统。多核并不能解决由登纳德缩放定律终结带来的能效计算挑战。每个活跃的核都会消耗能量,无论其对计算是否具有有效贡献。一个主要的障碍可以用阿姆达尔定律(Amdahl’s Law)表述,该定理认为,并行计算机的加速受限于序列计算的部分。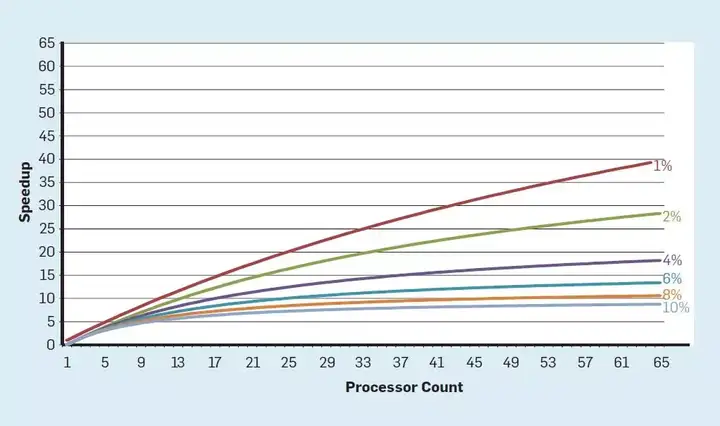
但是在核增多的情况下,运算速度的提升伴随的是大量能量的浪费。受制于多核的热耗散功率,会带来效应。暗硅效应指的是,虽然我们可以不断增加处理器核心的数量,但是由于能耗限制,无法让它们同时工作。为了解决这些问题,对架构师们又是新的挑战。
一种更加以硬件为中心的设计思路是设计针对特定问题和领域的架构,并给与它们强大的性能,这就是特定领域的体系架构(Domain-Specific Architecture)。DSA 通常被称为加速器,因为与在通用 CPU 上执行整个应用程序相比,它们可以加速某些应用程序。常见的DSA有图形加速单元GPU,神经网络处理器,以及软件定义处理器(SDN)。 DSA的优点是:1.DSA 为特定领域的计算使用了更加有效的并行形式;2.DSA 可以更有效地利用内存层次结构;3.DSA 可以使用较低的精度进行计算;4.DSA 受益于以特定领域语言(DSL)编写的目标程序,这些程序可以实现更高的并行性,更好的内存结构访问和表示,并使应用程序更有效地映射到特定域的处理器。
与此同时,开放式的ISA架构帮助开源生态系统,加上硬件敏捷开发的思想,硬件不光加速了性能,也加速了商业应用的速度。
硬件加速发展史
硬件加速并不是一个新概念了。就拿GPU举例,在1986年就有图像处理单元的概念,但是当时是严格意义上只用来处理图像的。NVIDIA第一部商业推出的GPU是在2009年的GeForce 256 。而通用图形处理器GPGPU(General-purpose computing on graphics processing units)友NVIDIA和ATI(现归AMD)于2007年推出他们的3D图形卡,拥有更多功能,像Unified Pixel Shaders,可以用在矩阵乘法,快速傅里叶变换,波形变换等。
2008年,苹果开发了针对这些性能的编程结构OpenCL,并广泛被AMD,IBM, Qualcom, Intel 甚至英伟达采用。但是NVIDIA并没有放弃他们的框架CUDA。如今,CUDA已成为高速,高吞吐量GPU计算的实际标准。 它本质上是一个软件层,可直接访问GPU的虚拟指令集和并行计算元素,以执行计算内核。如今,一个GPU可以集成非常多的核心,非常适合高吞吐的应用场景。
当然了,GPU只适合重复性比较高,操作之间比较独立,计算密集型的场景,所以并不能代替通用的CPU。
GPU在流处理,数据库和数据分析,机器学习等方面广泛应用,以较低的clock speed牺牲latency,以便在每个clock cycle获得更高的吞吐量,这一点是与CPU相反的。但总的来说,运行效率增加了。
针对不同的场景,我们还有FPGA和ASIC,但是要付出的代价是不一样的。
FPGA(现场可编辑逻辑阵列,Field Programmable Gate Arrays (FPGA))是一种高速的,可编程的芯片。他们可以在被生产出来后进行编程,并提供不菲的性能。由于成本问题,只能在一些特定的设备上看到,例如医疗设备,汽车,专业设备等等。相比于CPU,FPGA提供更高的带宽,更低能耗。但是可能太适合浮点运算,同时目前还是比较难调试的。 在数据处理方面,FPGA比较适合简单重复性的工作。目前的一些应用有Microsoft’s Project Brainwave(一个实时的AI推断平台), the Swarm64 Database Accelerator for Postgres(关系数据库加速),the Xilinx Alveo Data Center Accelerator(数据加速板卡), IBM’s Netezza(一个数据库加速解决方案)
ASIC(定制设计专用集成电路,Custom designed Application-Specific Integrated Circuits (ASIC) )是一种高度定制的芯片,主要用于音频处理,视频编码和网络等方面用作数字信号处理器。大批量生产的时候价格才算便宜。
小结:不同处理器比较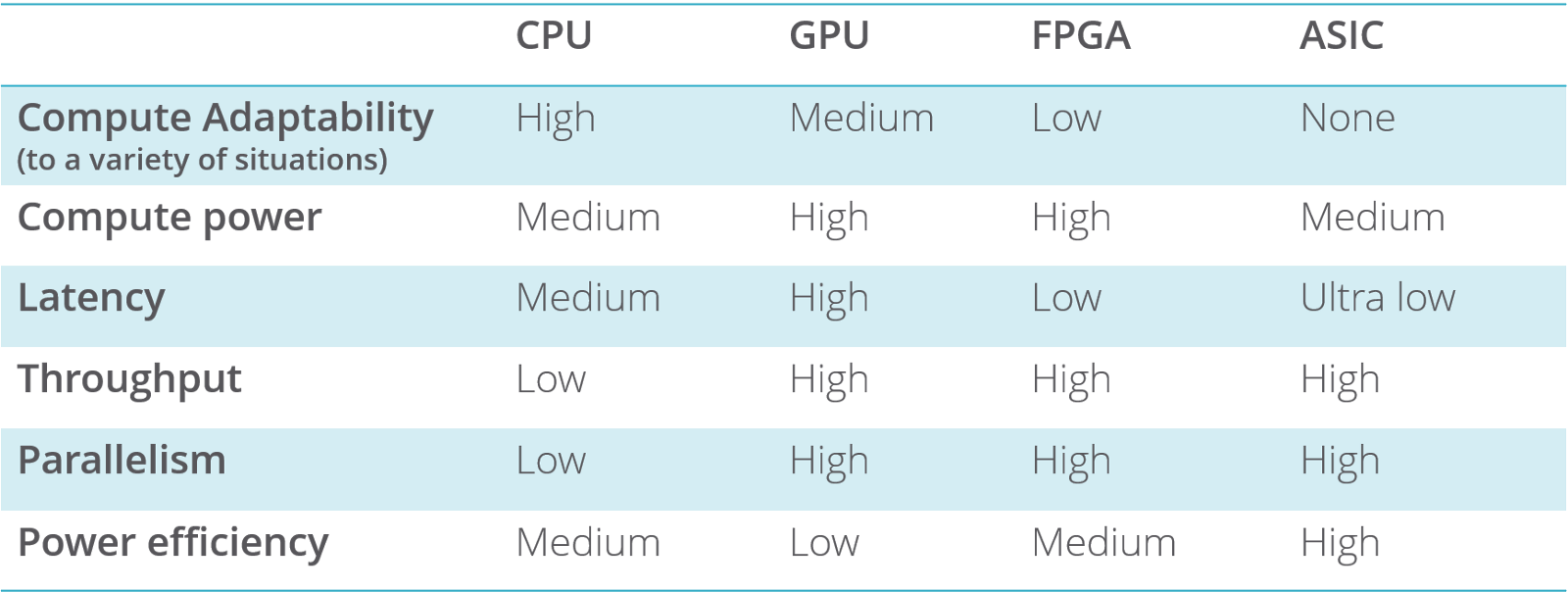
未来不只是cpu的,x86是经典,但不会一直统治下去。CPU加协处理器,或者叫加速器是一种提高并行项目吞吐的解决方案。机器学习,数据库加速,云计算会对硬件加速的需求越来越高
FPGA的突进
拿数据中心举例,数据中心业务会越来越广,从市场规模看,到2023年体量预计超 3000亿美元,加速器市场在2021年会超过200亿美元,FPGA市场在2022年会超过75亿美元。无论对于FPGA厂商、加速卡供应商,还是服务器供应商,都是前途一片光明。
从2018年,Xilinx开始提出数据中心优先,构建万物互联的理念,和众多硬件厂家成为合作伙伴,发布自己的加速板卡和解决方案。国内百度联合赛灵思的FPGA,构建软硬一体AI平台,实现了AI技术的标准化、自动化、模块化。阿里云异构FPGA计算经过了2018年和2019年两次双十一大促的考验,并且正在邀请合作伙伴将算力部署在阿里云上。2019年底,英特尔推出Stratix 10 GX 10M FPGA,包含1020 万个逻辑单元,433亿晶体管,成为当前密度最高的FPGA芯片。市面上一些初创公司也推出了基于PCIE方案的加速卡。 Intel推出了oneAPI,提供统一编程模型,简化跨不同架构的开发;Xilinx推出了软硬件统一平台Vitis,并将其开源。未来的FPGA市场,作为硬件加速的突起异军,开启群雄逐鹿。
FPGA的应用实例
-以金融科技为例
证券交易领域对于低时延的交易一直存在着需求,业内均在寻求搭建低时延交易系统的解决方案,基于GPU、FPGA硬件并行加速的技术逐渐进入证券交易领域。
FPGA具有硬件可编程、低功耗、低时延的特性。基于RTL(Register Transfer Level:寄存器传输级)级的逻辑编程,可定制化各类通讯协议(如TCP/IP协议栈卸载)、各种消息编解码(如上交所的FAST协议解码)及系统各种颗粒度的操作,实现数据的并行处理和流水操作,达到极低的系统时延和极高的系统容量。
上交所从2015年开始启动FAST行情,新的解决方案需要能快速更新,并适应不断变化的业务需求。
相比CPU以及GPU,FPGA更适合计算密集型任务。FPGA同时拥有流水线并行和数据并行,而GPU只有数据并行。FPGA是由存放在片内RAM中的程序来设置其工作状态的,因此工作时需要对片内的RAM进行编程。用户可以根据不同的配置模式,采用不同的编程方式。加电时,FPGA芯片将EPROM中数据读入片内编程RAM中,配置完成后,FPGA进入工作状态。掉电后,FPGA恢复成白片,内部逻辑关系消失,因此,FPGA能够反复使用。不同的编程数据,可以产生不同的电路功能。因此,FPGA的使用非常灵活,设计也有规范的流程。
招商证券也设计了基于FPGA-CPU的异构模式,“通过FPGA来实现TCP /IP 协议栈以及以太网MAC控制器,将原本属于主CPU的这部分工作卸载到额外的硬件电路完成,减轻CPU的负担,减少I/O交互环节,加速网络处理的能力,能极大提升系统的性能。”
由下往上分为五个逻辑层次,包括FPGA基础通信层、FPGA行情业务层、行情管理层、Host-FPGA接口层和Host管理服务层,层次之间设计开发边界明确,上层依赖下层模块,调用下层或同层模块的接口,上下层之间功能充分解耦,如图所示。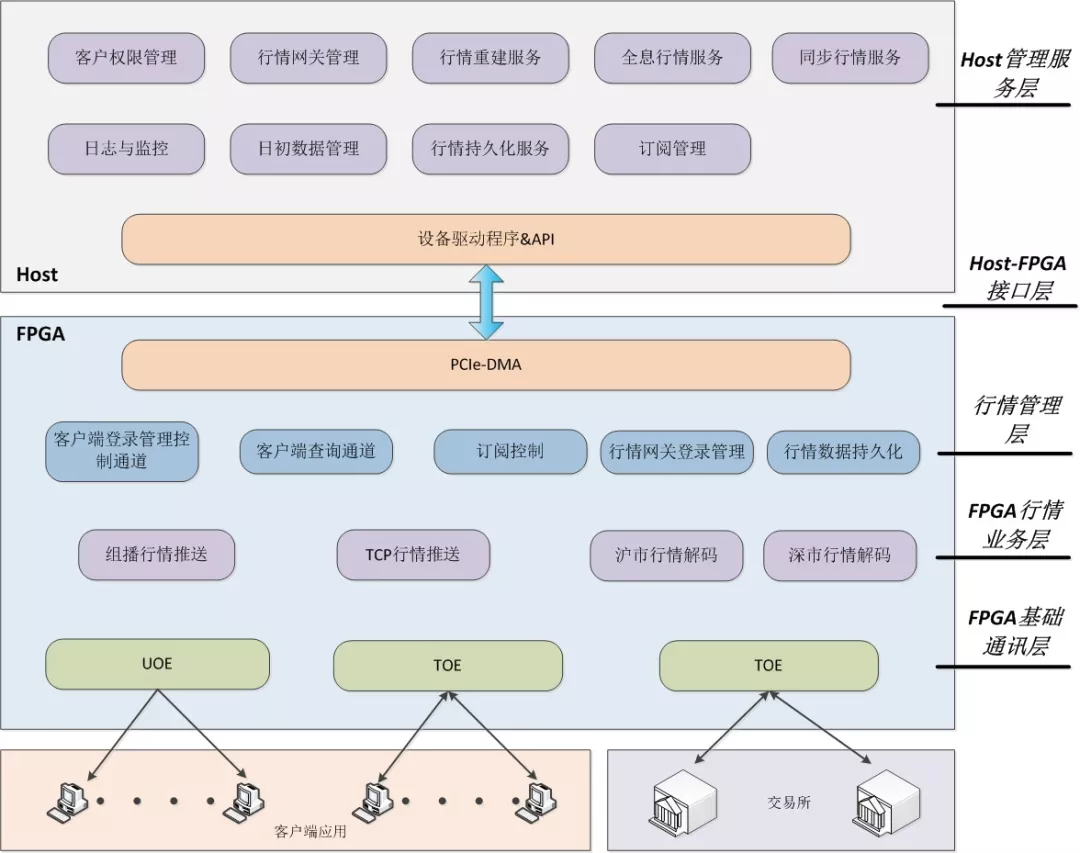
能够提供1000倍的提速效果和超高吞吐率。
TOE
TOE技术。在主机通过网络进行通信的过程中,主机处理器需要耗费大量资源进行多层网络协议的数据包处理工作,这些协议包括传输控制协议(TCP)、用户数据报协议(UDP)、互连网协议(IP)及互连网控制消息协议(ICMP)等。为了将占用的这部分主机处理器资源解放出来专注于其他应用,人们发明了TOE(TCP/IPOffloadingEngine)技术,将上述主机处理器的工作转移到网卡上。由于采用了硬件的方式进行处理,因此为网络传输提供了更高的性能。
全栈式加速解决方案
take中科驭数as an example : http://yusur.tech
总结
从接口到架构,硬件加速是未来数据中心,云计算、云存储,网络,AI,机器学习等方向的有力助推。
一些东西会在后续补充。
References:
1. Hennessy, J. L., & Patterson, D. A. J. C. A. (2019). A new golden age for computer architecture. 62(2), 48-60.
2.https://zhuanlan.zhihu.com/p/86698219
3.实战丨基于FPGA的证券行情加速实践
4.后摩尔定律的新型计算范式
5.【交易技术前沿】基于FPGA技术的FAST行情解码研究 / 钟浪辉,陈敏,陈坚,刘啸林,秦轶轩,李道双
6.A gentle introduction to hardware accelerated data processing